Alperen TercanHi! I am a PhD student in Electrical and Computer Engineering at University of Michigan, advised by Prof. Necmiye Ozay. My research broadly focuses on abstractions, robustness, constraints, and preference learning in RL. A brief statement of my research interests and prior work can be found here. Previously, I was a research intern at Max Planck Institute for Software Systems in Dr. Adish Singla's Machine Teaching group. I received my master's in Computer Science from Colorado State University, where I worked on Reinforcement Learning and Formal Methods under the supervision of Prof. Vinayak Prabhu and Prof. Chuck Anderson. My thesis topic was "Solving MDPs with Thresholded Lexicographic Ordering Using Reinforcement Learning". See my thesis here. My research goal is to build intelligent systems that can reliably solve challenging real-world problems. To this end, I enjoy combining ideas/tools from formal methods, symbolic reasoning, and machine learning. For example, I am interested in designing neuro-symbolic systems that can combine the recent developments in deep learning with the traditional approaches based on symbolic reasoning. Such a synthesis has the potential to bridge the current gap between real-world applicability and success stories from burgeoning AI fields like Reinforcement Learning (RL) by allowing safe, provable, explainable, and sample-efficient learning. While working towards this goal, there are things that make me particularly appreciate the journey: finding interesting high-level ideas, developing them to complete systems through rigorous theoretical analysis, adopting concepts and utilizing tools from different fields, and collaborating with researchers from diverse backgrounds. Previously, I graduated with a B.S in Electrical and Electronics Engineering from Bilkent University, Turkey. |

|
ResearchPlease see below for my main research work. |
|
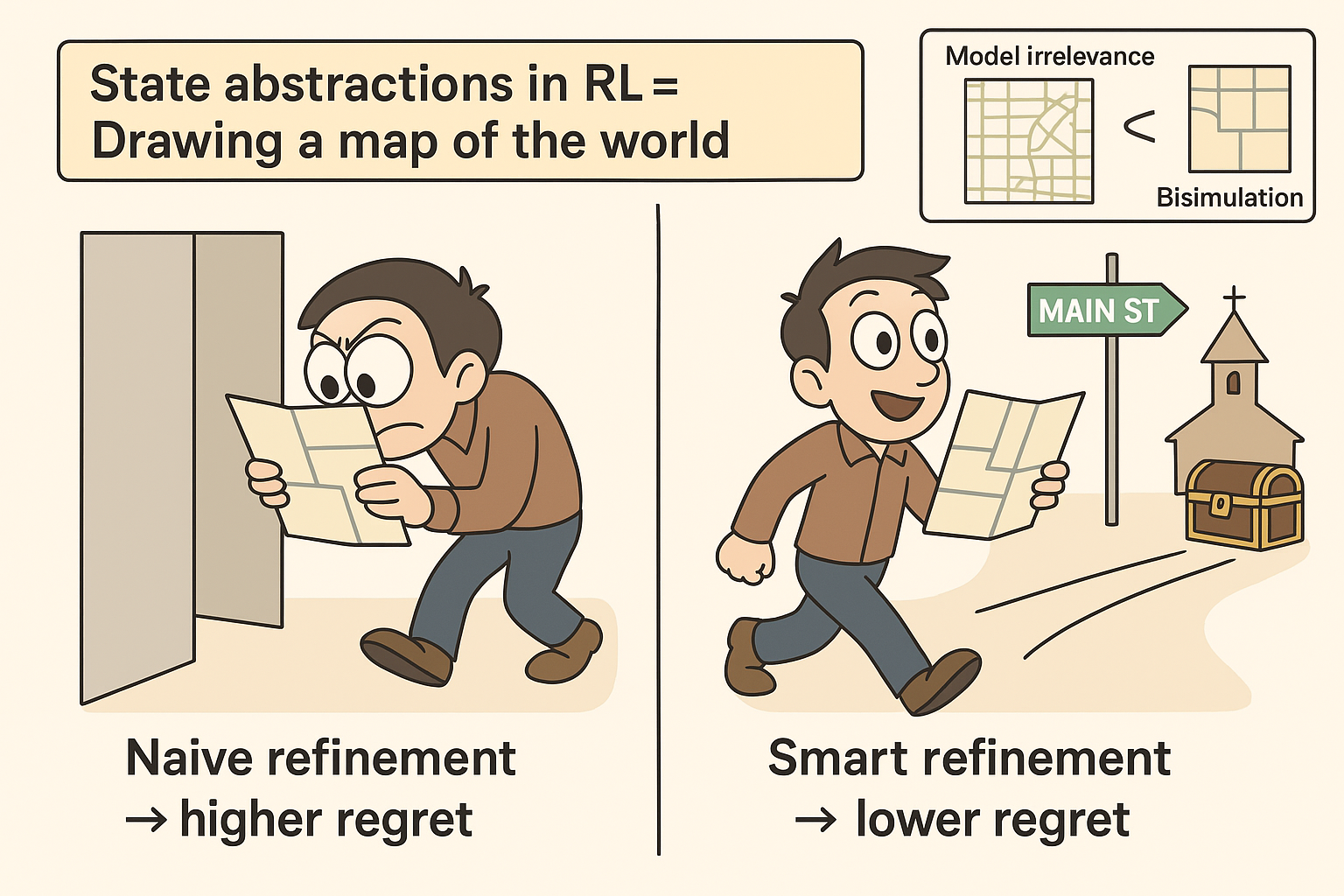
On the relation of bisimulation, model irrelevance, and corresponding regret boundsAlperen Tercan, Necmiye Ozay NeurIPS 2025 Workshop on Aligning Reinforcement Learning Experimentalists and Theorists link / State abstraction is a key tool for scaling reinforcement learning (RL) by reducing the complexity of the underlying Markov Decision Process (MDP). Among abstraction methods, bisimulation has emerged as a principled metric-based approach, yet its regret properties remain less understood compared to model irrelevance abstractions. In this work, we clarify the relationship between these two abstraction families: while model irrelevance implies bisimulation, the converse does not hold, leading to coarser abstractions under bisimulation. We provide the first regret bounds for policies derived from approximate bisimulation abstractions, analyzing both |
|
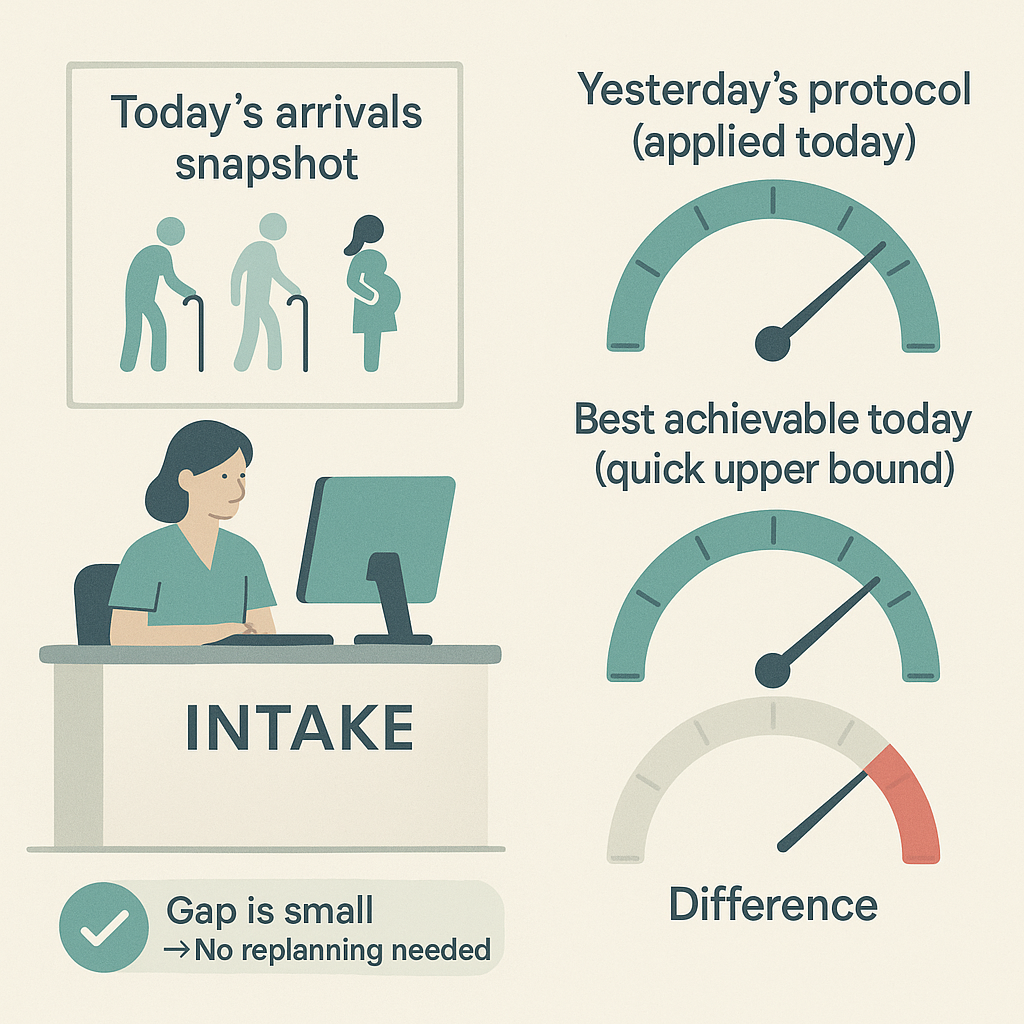
Initial Distribution Sensitivity of Constrained Markov Decision ProcessesAlperen Tercan, Necmiye Ozay Conference on Decision and Control 2025 link / Constrained Markov Decision Processes (CMDPs) are notably more complex to solve than standard MDPs due to the absence of universally optimal policies across all initial state distributions. This necessitates re-solving the CMDP whenever the initial distribution changes. In this work, we analyze how the optimal value of CMDPs varies with different initial distributions, deriving bounds on these variations using duality analysis of CMDPs and perturbation analysis in linear programming. Moreover, we show how such bounds can be used to analyze the regret of a given policy due to unknown variations of the initial distribution. |
|
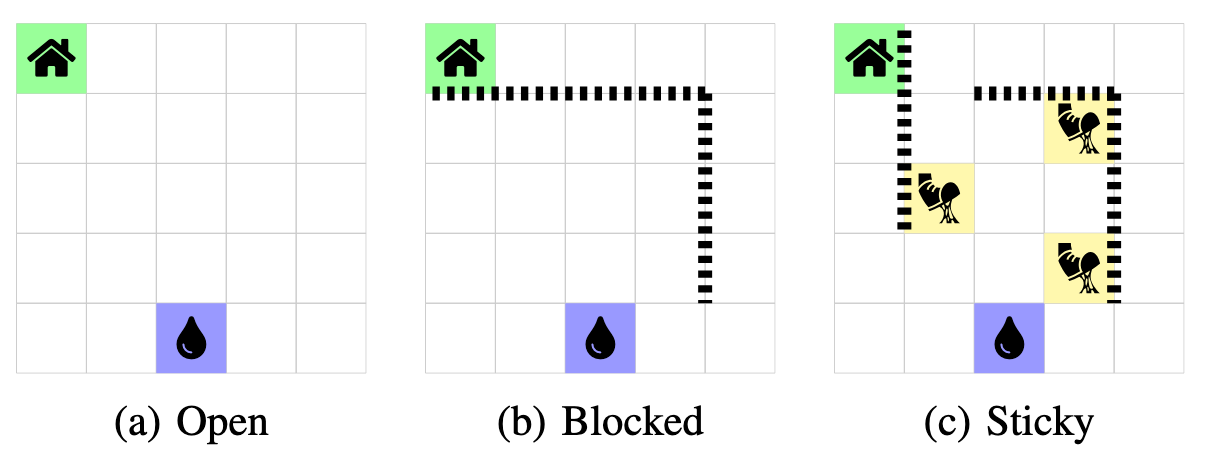
Efficient Reward Identification In Max Entropy Reinforcement Learning with Sparsity and Rank PriorsMohamad Shehab*, Alperen Tercan*, Necmiye Ozay Conference on Decision and Control 2025 link / In this paper, we consider the problem of recovering time-varying reward functions from either optimal policies or demonstrations coming from a max entropy reinforcement learning problem. This problem is highly ill-posed without additional assumptions on the underlying rewards. However, in many applications, the rewards are indeed parsimonious, and some prior information is available. We consider two such priors on the rewards: 1) rewards are mostly constant and they change infrequently, 2) rewards can be represented by a linear combination of a small number of feature functions. We first show that the reward identification problem with the former prior can be recast as a sparsification problem subject to linear constraints. Moreover, we give a polynomial-time algorithm that solves this sparsification problem exactly. Then, we show that identifying rewards representable with the minimum number of features can be recast as a rank minimization problem subject to linear constraints, for which convex relaxations of rank can be invoked. In both cases, these observations lead to efficient optimization-based reward identification algorithms. Several examples are given to demonstrate the accuracy of the recovered rewards as well as their generalizability. |
|
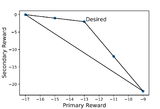
Thresholded Lexicographic Ordered Multi-Objective Reinforcement LearningAlperen Tercan, Vinayak Prabhu European Conference of Artificial Intelligence (ECAI) 2024 link / Our work on solving multi-objective control tasks with lexicographic preferences and {temporal logic-based reward specifications} required me to combine my knowledge and expertise in optimization, RL, and formal methods. In this work, I’ve developed a taxonomy of control tasks with thresholded lexicographic objectives and used it to show how the current RL approaches fail in certain settings. Then, I discussed several fixes to current methods to improve their performance. Finally, I proposed and tested a novel policy gradient algorithm based on hypercone projections of the policy gradients. |
|
|
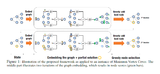
Synthesizing a Progression of Subtasks for Block-Based Visual Programming TasksAlperen Tercan et al. AAAI2024 Workshop on AI for Education link / The state-of-the-art neural program synthesis methods fail for relatively complex problems(finding the mid-point of a line) which require multiple level nesting. Therefore, we developed a task decomposition framework which can automatically break any task into simpler subtasks that progressively lead to the original task. These subtasks can be used to create a curriculum for faster learning. We then tested the effectiveness of our approach for an RL agent in solving neural program synthesis problems. Moreover, we conducted a user study to evaluate the effectiveness of our task decomposition for human learners who try to solve complex Karel tasks. |
|
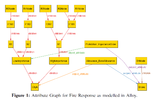
Provable Stateful Next Generation Access Control for Complex Dynamic SystemsIn Preparation link / code / Many real-world problems require flexible, scalable, and fine-grained access control policies. Next Generation Access Control(NGAC) framework inherits these traits from Attribute Based Access Control(ABAC) and provides an intuitive graph-based approach. In this work, we augment NGAC framework with multi-level rule hierarchy and stateful policies. Then, we show how an NGAC policy can be analyzed together with an environment model using Alloy. This allows defining complex dynamic systems and keeping policies still tractable for automated analysis. We present our approach on emergency fire response problem. |
|
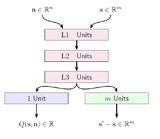
Increased Reinforcement Learning Performance through Transfer of Representation Learned by State Prediction ModelAlperen Tercan, Charles W. Anderson 2021 International Joint Conference on Neural Networks (IJCNN) link / code / slides / We propose using state change predictions as an unbiased and non-sparse supplement for TD-targets. By training a forward model which shares a Q-network’s initial layers, we allow transfer learning from model dynamics prediction to Q value function approximation. We discuss two variants, one doing this only in the initial steps of the training and another one using it throughout the training process. Both variants can be used as enhancements to state-of-the-art RL algorithms. |
Other ProjectsThese include coursework and side projects. |
|
Reinforcement Learning for Combinatorial Optimization over Graphsproject 2020-05-01 slides / In this project, the use of reinforcement learning for heuristics in graph algorithms is investigated. This line of research can be seen as an extension of general trend in computer science research to replace rule-based, hand-crafted heuristics with data-driven methods. The project focus was identifying possible future research directions rather than a comprehensive survey of the field. |
|
Design and source code from Leonid Keselman's website |